Olink Explore HT および Olink Reveal は、Proximity Extension Assay(PEA)テクノロジーに基づくマルチプレックス型高スループットバイオマーカー解析プラットフォームです。PEAテクノロジーは、抗体ベースの免疫測定法と次世代シーケンス(NGS)の強力な特性を組み合わせたものです。これにより、最小限のサンプル量を使用しながら、卓越した特異性と感度を備えたスケーラブルなマルチプレックスタンパク質バイオマーカープラットフォームを提供します。Olinkは、臨床研究の多様な分野において、プロテオミクスプロファイリング、バイオマーカーの発見、メカニズムの理解を可能にします。

Olink Explore HTおよびOlink Revealの認定Olinkサービスプロバイダー
- 当社は、Olinkの先進的なプロテオミクスプラットフォームを活用し、高スループットかつ高品質なタンパク質バイオマーカー発見サービスを提供する世界初のプロバイダーの一つです。
- Olinkのコンコーダンステストに合格することで、当社のサービス品質がOlinkの厳格なデータ提供基準と一致していることを検証しました。

Olink Explore HTとOlink Revealの主要な特徴
| Olink Explore HT | Olink Reveal | |
| ターゲット タンパク質 |
5,400以上 | 1,000以上 |
| アプリケーション |
|
|
| 反応あたりの サンプル量 |
2 μL | 4 μL |
| ランあたりの サンプル数 |
172+20の内蔵QCサンプル | 86+10の内蔵QCサンプル |
なぜプロテオミクス研究に Olink を選ぶのか?
- マルチプレックス:1つのサンプルで最大5,400種類のタンパク質マーカーを迅速に検出可能。大規模集団研究に対応。
- 高感度かつ広いダイナミックレンジ:検出感度はfg/mLからmg/mLまで対応。ダイナミックレンジは10桁に及び、高・中・低濃度のタンパク質を網羅的にカバー。
- 少量サンプルでの測定:各アッセイに必要なサンプル量はわずか2~4μL。
- 高いデータ再現性:テクニカル反復測定が不要で、質量分析など従来法と比べてもはるかに高い再現性。
- 高い特異性:PEAプロセスでは、各標的タンパク質に対して2種類の抗体を設計し、非特異的結合を回避。
- 低濃度血漿タンパク質の検出:Olinkは、質量分析ではサンプル前処理の段階で見逃される可能性のある低濃度血漿タンパク質を検出可能。
- 臨床タンパク質アッセイとの高い一致率:抗体ベースの免疫アッセイは臨床検査の主流技術であり、トランスレーショナルリサーチに適している。
- cis-pQTLとの高い相関:Olinkの結果は遺伝子変異と高い相関があり、マルチオミクス研究や大規模集団ビッグデータ解析を可能に。
UKバイオバンクおよび大手製薬企業による採用:UKバイオバンクから54,000人分のOlinkデータを研究目的でダウンロード可能。さらに50万人分のデータ作成も進行中。
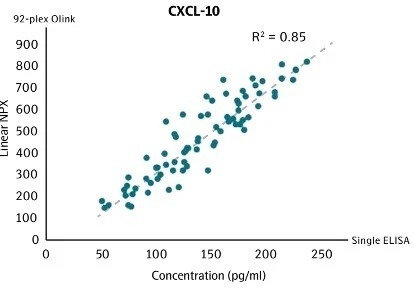
Correlation between conventional ELISA and Olink for CXCL-101
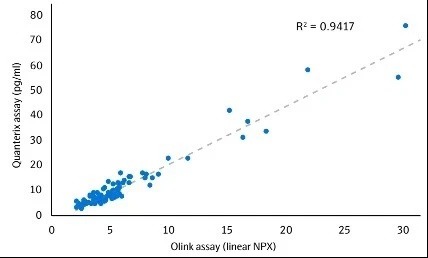
Correlation between Olink and SIMOA for NFL1
サンプル要件
| サンプルタイプ | サンプル量 | 保存/輸送状態 | その他 |
| 血清/血漿 | 1.5mLチューブに50μL以上 | サンプルの配送中の解凍を防ぐため、十分な量のドライアイスを同封し、冷凍便でお送りください。 | 抽出後すぐにサンプルを-80℃で保存してください。溶血により分析結果が影響を受ける可能性があります。 |
| 他のサンプル種 | 脳脊髄液,ライセートなど(詳細についてはお問い合わせください) | ||
*詳細についてはお問い合わせください。
Olink Explore HT & Reveal ワークフロー
サンプルとコントロールを96ウェルプレートに移し、一晩、培養します。この間、抗体がそれぞれの標的タンパク質に結合します。抗体に結合したオリゴヌクレオチドは近接し、ハイブリダイズし、その後PCR増幅により延長されます。増幅ステップにおいて各サンプルにユニークサンプルインデックスが導入され、ライブラリへのプールが容易になります。ライブラリはその後精製され、シーケンスされます。
サンプル準備、ライブラリ準備、シーケンス、データQCからバイオインフォマティクス解析まで、ノボジーンは高品質な製品と専門的なサービスを提供しています。各ステップは、高い科学的基準と細心の設計に従って実施され、高品質な研究結果を確保します。

より多くのツールと技術情報にアクセスできます:
- Explore HT(リンク: olink-explore-ht-assay-list.xlsx)またはReveal(リンク: https://olink.com/products/olink-reveal)の完全なアッセイリストへアクセス
- パスウェイブラウザ、研究規模計算ツール、その他のプロテオミクスツールにアクセスでき、グローバルなプロテオミクスコミュニティとつながることができるOlink Insightに登録(Log in to Olink Insight)
参考文献:
- Olink Proteomics. ホワイトペーパー. 2023年12月1日に取得
https://www.olink.com/content/uploads/2021/09/olink-strategies-for-design-of-protein-biomarker-studies-1098-v2.0.pdf
プロテオミクス研究における注目の論文
トップ論文を見る:https://olink.com/knowledge/publications
NPX値を用いたデータ正規化および品質管理
NPX(Normalized Protein eXpression)は、Olinkが使用する任意単位で、Log₂スケールで表されます。
シーケンス後、生データはカウントデータに変換され、検出されたコピー数に基づき、各アッセイとサンプルの組み合わせごとに整数値が割り当てられます。これらの生データカウントはNPX値に変換され、異なるサンプルセット間でのタンパク質レベルの変化を特定し、タンパク質シグネチャを確立することができます。一般的に、NPX値が高いほどタンパク質濃度が高いことを意味します。
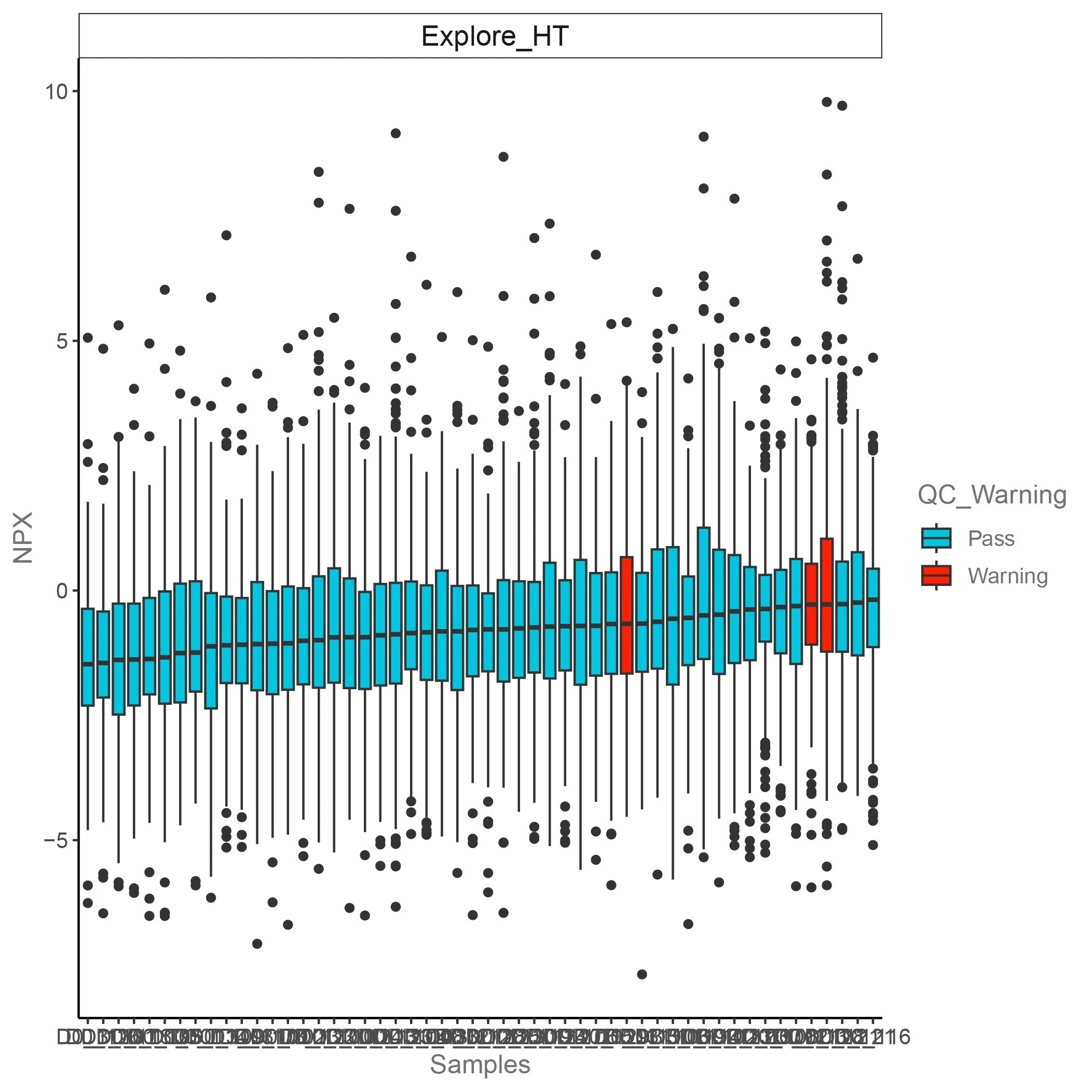
x軸はサンプル名を表します。y軸はNPX値を表します。赤いバーはQC警告サンプル、青いバーはQC合格サンプルを表します。
タンパク質発現の主成分解析(PCA)
主成分解析(PCA)は、大規模データセットを解析するために次元削減を行う統計的手法です。この解析では、NPXデータファイルに対してPCAを実施し、すべてのサンプルを選択した主成分に沿って散布図としてプロットします。これにより、関心のある変数に基づいてサンプルが分離またはクラスター化される様子を示すのに有用です。また、潜在的な外れ値サンプルを特定するためにも利用できます。
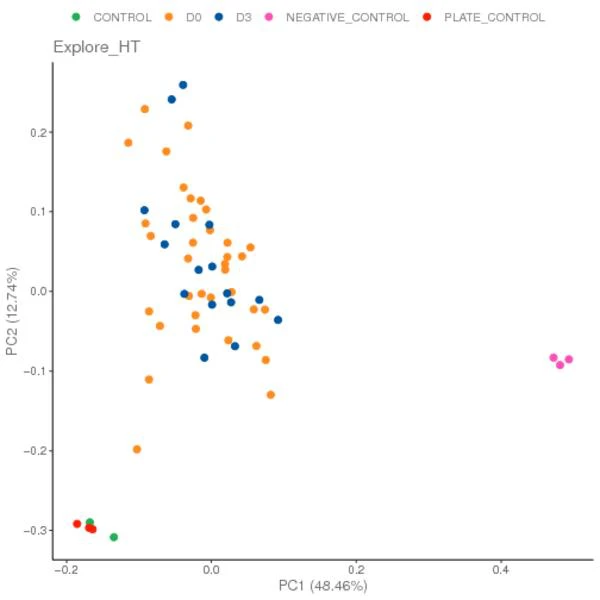
異なる色のドットは異なるグループを表します。サンプル間の距離が近いほど、サンプル間の類似性が高くなります。
タンパク質発現の階層的クラスタリング・ヒートマップ
階層的クラスタリングは、データの概要を把握し、タンパク質プロファイルに基づいて類似したサンプルやタンパク質のサブグループを特定するための手法です。この分析はしばしばヒートマップとして可視化され、類似したタンパク質やサンプルは互いに近い位置に配置されます。ヒートマップ上では、タンパク質発現レベルが色のグラデーションで表現されます。
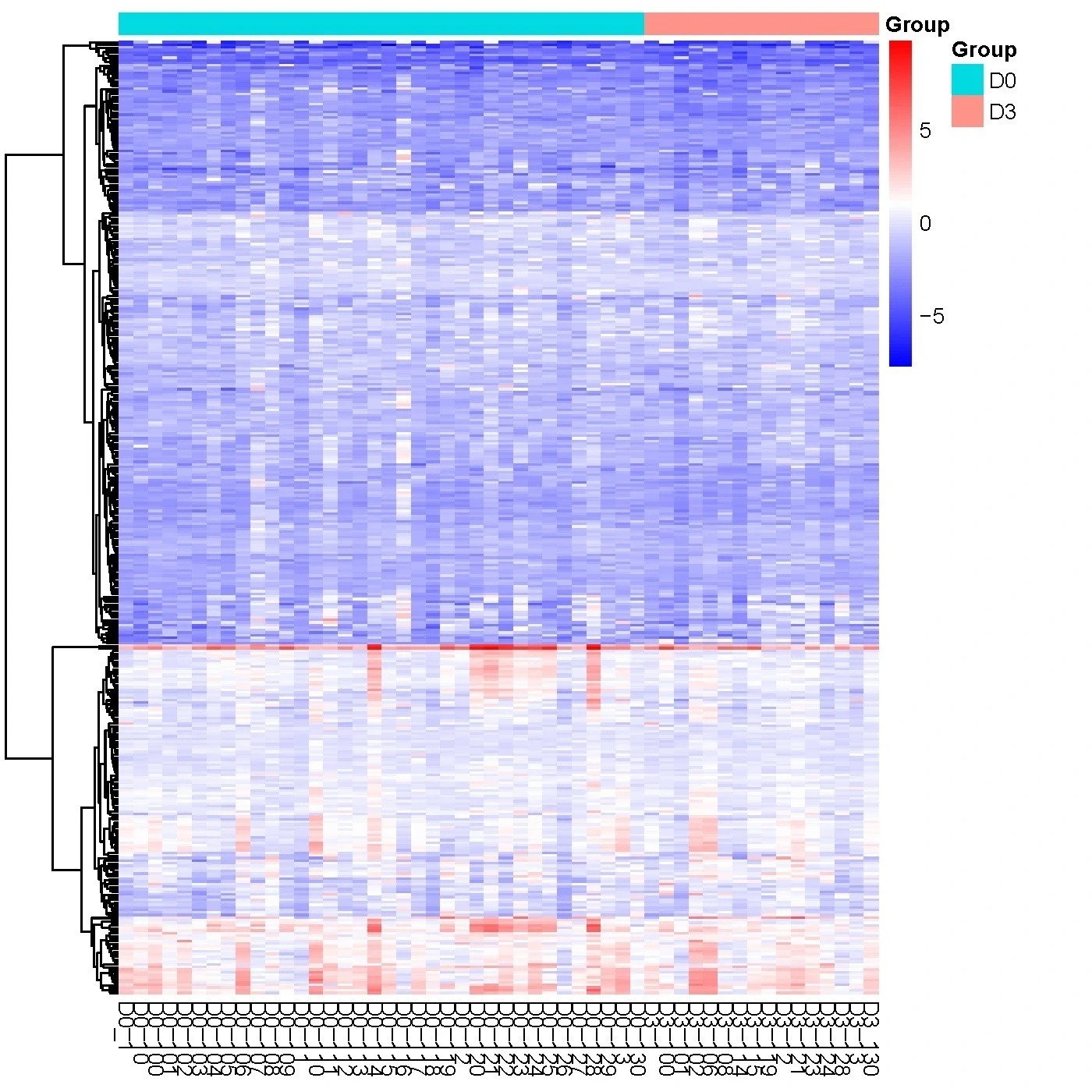
赤色はNPX発現レベルが高いタンパク質を示し、青色はNPX発現レベルが低いタンパク質を示します。赤色から青色への色の変化は、NPX値が大きいものから小さいものまでの範囲を示しています。
タンパク質変動発現解析のボルケーノプロット
グループ間のタンパク質発現レベルの比較は、t検定またはANOVAを用いて実施され、その結果はボルケーノプロットで可視化されます。
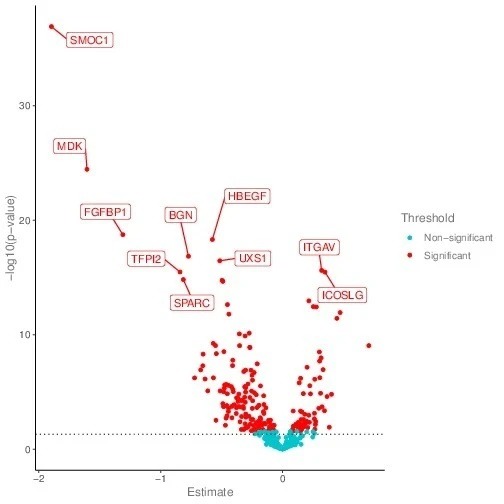
X軸は2つのグループ間のNPX差、Y軸は-log(p値)(10を底とする)を示します。NPX差 = NPX.group1 – NPX.group2。
赤色の点は有意な発現差のあるタンパク質を表します。青色の点は有意な発現差のないタンパク質を表します。
GO(Gene Ontology)エンリッチメント解析
GOはGene Ontology(http://www.geneontology.org/)の略語で、すべての生物種において遺伝子の性質の表現を統一するための主要なバイオインフォマティクス分類システムです。
GOは以下の3つの主要カテゴリーで構成されます:細胞構成要素(cellular component)、分子機能(molecular function)、生物学的プロセス(biological process)padj < 0.05 のGO用語は、有意にエンリッチされているとみなされます。
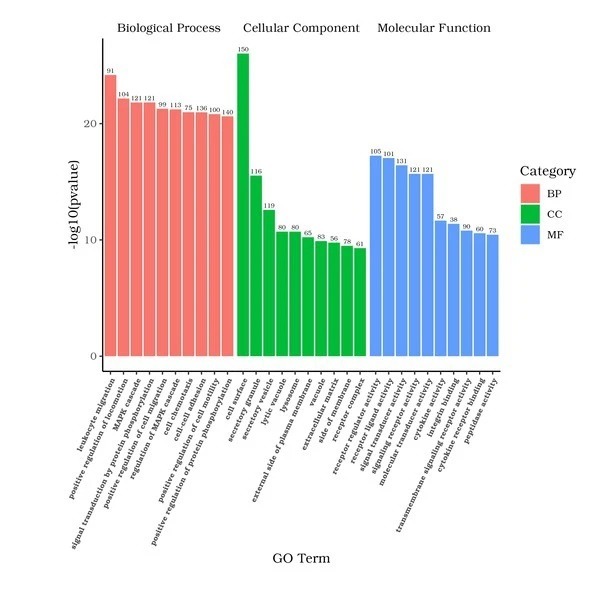
x軸はGO Termを表し、y軸は各GO Termのエンリッチメントの有意水準(-log10(padj)で表されます)を示します。異なる機能カテゴリーは異なる色で表されます。
デモレポートをご希望でしたらお問い合わせください。